Project Overview
This project implements a modular natural language processing (NLP) pipeline designed to extract structured insights from user-generated review data. While the film Oppenheimer is used as a representative example, the system is designed to generalize across any review-based corpus. The pipeline begins with asynchronous data collection from the Letterboxd platform, followed by language filtering, dual-path sentiment classification using both a transformer-based BERT model and a rule-based TextBlob method, and unsupervised topic modeling. Each review is annotated with both sentiment and topic labels, enabling comparative analysis between modeling approaches and the generation of a topic-sentiment matrix. All components are organized as standalone Python scripts to support staged execution, debugging, and traceability. The final outputs include structured datasets and visualizations that highlight the performance differences between traditional and transformer-based sentiment analysis, supporting downstream tasks such as semantic evaluation, recommendation prototyping, and audience feedback modeling.
Module: fetch_letterboxd.py
This module initiates the pipeline by collecting user-generated reviews from the Letterboxd platform. It employs asynchronous scraping via Playwright to automate browser interactions and retrieve content from up to 300 paginated review pages. The script launches a headless Chromium browser and iteratively navigates each page, extracting all paragraph (<p>) elements as candidate review blocks. To ensure data quality, it filters out entries that are too short, contain copyright markers, or match known noise patterns. A safeguard mechanism halts scraping early if five consecutive pages yield insufficient content, preventing unnecessary requests and preserving system resources. Valid reviews are stored in a structured CSV file (data/letterboxd_reviews.csv), with each row representing a cleaned user comment. This module serves as the data acquisition entry point for the pipeline, providing a reproducible and fault-tolerant method for sourcing real-world review data suitable for downstream NLP tasks.
Module: detect_language.py Following the initial data acquisition, this module performs automatic language detection on the raw review dataset collected from Letterboxd. Its primary function is to identify and label the language of each review, enabling downstream filtering and ensuring that only English-language content is retained for further analysis. The script reads the input CSV file (letterboxd_reviews.csv) and applies a safe detection function to each entry using the langdetect library. To maintain robustness, the function includes exception handling and length checks—reviews shorter than 10 characters or those that trigger detection errors are labeled as "unknown". After processing, the script appends a new column named language to the dataset and writes the result to a new file (letterboxd_reviews_labeled.csv). This output serves as the foundation for subsequent filtering steps, such as excluding non-English reviews prior to sentiment classification and topic modeling. The module is lightweight and fault-tolerant, ensuring that noisy or incomplete input data does not interrupt the pipeline’s execution.
Module: sentiment(classic_TextBlob).py The first sentiment classification path in the pipeline uses a traditional rule-based method built on TextBlob. This module reads the labeled review dataset produced by the language detection step and filters for English-language entries. For each review, it computes a polarity score ranging from –1 (strongly negative) to +1 (strongly positive), representing the emotional tone of the text. Reviews that fail to parse are assigned a default score of 0 to maintain pipeline stability. Based on the computed score, each review is categorized into one of three sentiment classes: "positive" (score > 0.2), "negative" (score < –0.2), or "neutral" (score between –0.2 and 0.2). These labels are added to the dataset and saved to a structured output file (letterboxd_reviews_sentiment.csv). This module provides a lightweight and interpretable baseline for sentiment analysis, suitable for exploratory tasks and rapid prototyping. Its simplicity allows for fast execution, but it may struggle with nuanced or informal language.
Module: sentiment(BERT).py In parallel with the TextBlob-based approach, this module applies a transformer-based sentiment classification using a pretrained BERT model (nlptown/bert-base-multilingual-uncased-sentiment). After filtering for English-language reviews, the script applies additional content-based heuristics to exclude non-review entries such as platform disclaimers, spoiler warnings, and irrelevant or inappropriate text. The remaining reviews are passed to a Hugging Face sentiment pipeline, which outputs a star rating prediction (1–5 stars). These ratings are mapped to three sentiment classes: "negative" (1–2 stars), "neutral" (3 stars), and "positive" (4–5 stars). The classification results are appended to the dataset and saved to the same output file (letterboxd_reviews_sentiment.csv), enabling direct comparison with the TextBlob results. This module offers improved semantic understanding and robustness, especially for informal or ambiguous expressions. While computationally heavier, the BERT-based approach demonstrates higher accuracy and adaptability, making it suitable for production-grade sentiment modeling.
Module: topic_modeling.py After sentiment classification, the pipeline proceeds to unsupervised topic modeling to uncover latent thematic structures within the review corpus. This module reads the sentiment-labeled dataset (letterboxd_reviews_sentiment.csv) and applies a bag-of-words vectorization using CountVectorizer, configured with English stopword removal and frequency thresholds to eliminate overly common or rare terms. The resulting document-term matrix is passed to a Latent Dirichlet Allocation (LDA) model with five components, each representing a distinct topic. For interpretability, the module prints the top keywords associated with each topic, allowing manual inspection of thematic coherence. Each review is then assigned a dominant topic based on its highest probability score in the topic distribution matrix. The enriched dataset, now containing both sentiment and topic labels, is saved to letterboxd_reviews_topic.csv. This module enables the construction of a topic-sentiment matrix and supports downstream tasks such as representative comment extraction and semantic clustering. Its design balances interpretability and scalability, making it suitable for exploratory analysis and prototyping.
Module: extract_representative.py With both sentiment and topic labels assigned, the pipeline proceeds to extract representative reviews for each topic-sentiment pair. This module reads the enriched dataset (letterboxd_reviews_topic.csv) and groups the reviews by topic and sentiment category. For each group, it selects the longest review as a representative sample, under the assumption that longer entries tend to be more expressive and informative. The selected reviews are compiled into a new dataset containing one entry per topic-sentiment combination. This output is saved to representative_reviews.csv, providing a concise and interpretable summary of the corpus. These representative comments can be used for reporting, qualitative analysis, or as illustrative examples in downstream applications such as recommendation systems or feedback dashboards. The module emphasizes clarity and modularity, enabling easy substitution of selection criteria or integration with visualization tools.
Module: visualize.py
As the final step in the pipeline, this module generates a visual summary of the sentiment distribution across discovered topics. It reads the enriched dataset (letterboxd_reviews_topic.csv) and aggregates review counts by topic and sentiment label. Using matplotlib and seaborn, the module produces a stacked bar chart that displays how positive, neutral, and negative reviews are distributed across each topic. The chart is saved as a PNG image (sentiment_per_topic.png) and provides an interpretable overview of emotional trends within the corpus. This visualization supports exploratory analysis, reporting, and presentation use cases, and serves as a compact summary of the pipeline’s output. The module is lightweight and modular, allowing easy adaptation to alternative chart types or integration with dashboard frameworks.
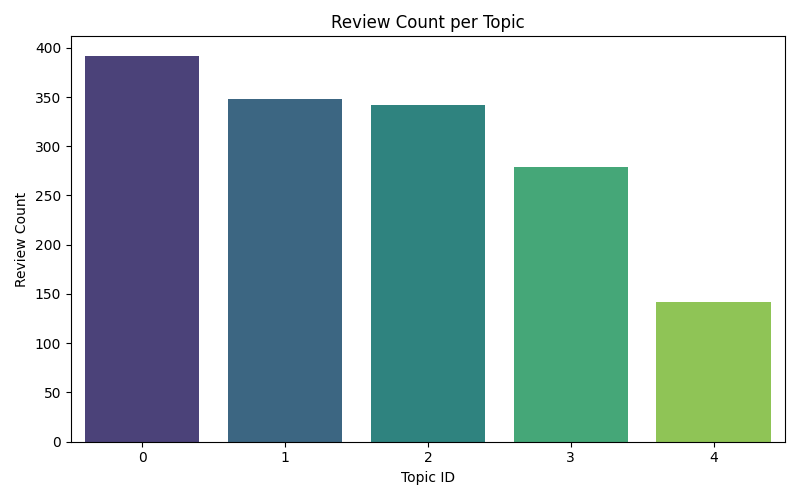
Module: visualize_sentiment.py Complementing the sentiment visualization module, this script generates a statistical overview of topic distribution within the review corpus. It reads the topic-labeled dataset (letterboxd_reviews_topic.csv) and counts the number of reviews assigned to each topic. Using seaborn and matplotlib, it produces a bar chart that displays the volume of reviews per topic, providing a high-level summary of thematic coverage. The chart is saved as a PNG image (topic_distribution.png) and serves as a diagnostic tool for evaluating topic balance and model granularity. This visualization supports exploratory analysis and helps validate the effectiveness of the LDA topic modeling step. Like other modules in the pipeline, it is lightweight, reproducible, and easily extensible for alternative visual formats or integration into reporting workflows.
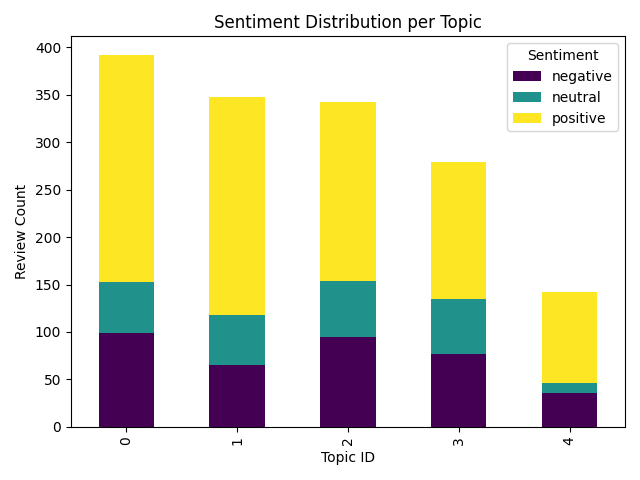
The two visualizations generated in the final stage of the pipeline offer complementary insights into the structure and emotional tone of the review corpus. The first chart, Sentiment Distribution per Topic, reveals how emotional polarity varies across different thematic clusters. Notably, Topic 0 exhibits the highest volume of reviews, with a dominant share of positive sentiment, while Topic 4 shows the lowest engagement. Across all topics, positive sentiment appears to be the most prevalent, suggesting a generally favorable reception of the film within the sampled audience.
The second chart, Review Count per Topic, provides a quantitative overview of topic distribution, highlighting which thematic areas attracted the most user commentary. This helps validate the granularity of the LDA topic modeling and supports downstream decisions such as representative comment selection or targeted content analysis.
Beyond visualization, this project incorporates a dual-path sentiment analysis architecture—comparing a rule-based method (TextBlob) with a transformer-based BERT model. To evaluate the reliability of each approach, selected outputs were manually reviewed and also submitted to large language models (LLMs) such as ChatGPT and Grok for secondary assessment. These models, with their advanced semantic understanding, were able to detect subtle linguistic features such as sarcasm, irony, and emotional undertones that traditional methods often miss.
The evaluation revealed that BERT consistently outperformed TextBlob in capturing nuanced sentiment, especially in informal or ambiguous reviews. While TextBlob offers speed and interpretability, its rule-based logic lacks the depth required for complex emotional inference. In contrast, BERT—though computationally heavier—demonstrated human-like sensitivity to context, making it more suitable for production-grade sentiment modeling.
This finding reinforces the value of transformer-based models in real-world NLP tasks and suggests that future pipelines should prioritize semantic depth over simplicity when emotional accuracy is critical.
Output Artifacts and Analytical Value
The pipeline produces a series of structured CSV files and visual assets, each aligned with a specific stage in the processing flow. These outputs are designed to be modular, interpretable, and suitable for both automated workflows and manual inspection. Together, they form a reproducible trace of the entire NLP process—from raw data acquisition to semantic interpretation.
Structured CSV Files
| letterboxd_reviews.csv | Raw scraped reviews from Letterboxd |
| letterboxd_reviews_labeled.csv | Reviews with detected language (language column) |
| letterboxd_reviews_sentiment.csv | Reviews with sentiment score and label (sentiment_score, sentiment_label) |
| letterboxd_reviews_topic.csv | Reviews with assigned topic index (topic) |
| representative_reviews.csv | One representative review per topic-sentiment combination |
These files support downstream tasks such as semantic clustering, model evaluation, and qualitative review. Each stage builds upon the previous, preserving traceability and enabling targeted debugging or refinement.
Visualizations
topic_distribution.png | Bar chart showing review count per topic |
| sentiment_per_topic.png | Stacked bar chart showing sentiment distribution across topics |
These visual assets provide intuitive summaries of the corpus structure. The topic distribution chart helps assess thematic coverage and model granularity, while the sentiment-per-topic chart reveals emotional trends across different thematic clusters. For example, Topic 0 shows both the highest review volume and a dominant positive sentiment, suggesting strong audience engagement and favorable reception.
Evaluation Context
These outputs also serve as inputs for manual review and large language model (LLM) evaluation. By submitting representative samples to human annotators or advanced models like ChatGPT or Grok, the pipeline enables deeper assessment of sentiment accuracy—especially in cases involving sarcasm, ambiguity, or emotional nuance. This dual evaluation strategy reinforces the comparative analysis between BERT and TextBlob, ultimately validating the transformer-based model’s superior performance in capturing complex linguistic signals.
All artifacts are saved to the data/ directory and can be reused, audited, or extended for future experiments, teaching modules, or production prototypes.