Co-teaching 的研究意义
在当前数字媒体系统的实际应用中,监督学习模型广泛用于内容分类、推荐排序、用户行为建模等任务。这类模型的训练高度依赖标签数据,而标签的生成往往来自用户行为日志、弱监督算法或人工标注,其准确性难以保证。标签错误不仅影响模型性能,还可能在实际部署中引发推荐偏差、审核误判、用户体验下降等问题,进而影响平台的业务稳定性与内容分发效率。
传统的经验风险最小化(ERM)训练策略在面对标签噪声时表现出明显的脆弱性。模型在训练过程中容易“记忆”错误标签,导致过拟合无效信息,尤其在标签错误率较高的场景中,模型性能迅速下降。这一问题在数字媒体平台中尤为突出,原因在于数据规模庞大、标签来源复杂、更新频率高,模型必须具备一定的鲁棒性才能维持长期稳定运行。
Co-teaching 是一种针对标签噪声问题提出的鲁棒训练策略,其核心机制是通过双网络互选小损失样本进行更新,从而在训练过程中动态过滤掉可能存在错误标签的数据。该方法不依赖外部知识或额外标注,结构简洁,易于嵌入主流模型体系,具备较高的工程适配性。
研究该策略的意义在于:一方面,它为数字媒体平台提供了一种可部署的训练优化方案,能够在弱监督或标签不确定性较高的环境下提升模型的泛化能力;另一方面,它推动了监督学习从理想数据假设向真实数据环境的适应,具有明确的理论价值与实践潜力。尤其在推荐系统、内容审核、自动标签生成等任务中,该策略可作为训练阶段的鲁棒性模块集成,提升整体系统的稳定性与业务表现。
1.背景介绍
在数字媒体系统的推荐与分类任务中,标签的准确性始终是一个难以回避的问题。平台上的训练数据往往来自用户行为日志、自动标签生成器或人工标注,这些标签在规模扩大和更新频率提升的背景下,不可避免地出现偏差。尤其在推荐系统中,模型需要根据用户的历史行为预测点击率或偏好分布,而这些行为本身就可能包含大量误点、刷量或非意图性操作。标签噪声在这种场景下不是偶发问题,而是结构性干扰。
本实验围绕这一问题构建了一个密集噪声率采样框架,在 CIFAR-10 数据集上对 Co-teaching 与标准 ERM 方法进行了系统对比。通过多随机种子运行与准确率趋势分析,观察模型在不同噪声强度下的收敛行为与性能波动。结果显示,在噪声率处于 0.25–0.50 区间时,Co-teaching 能显著提升模型的稳定性与泛化能力,有效抑制错误标签的影响;而在极高噪声率(≥0.70)下,其优势开始减弱,提示该策略在极端条件下仍需配合其他机制进行调优。
从系统部署的角度来看,Co-teaching 的价值不在于替代现有模型结构,而在于提供一种训练阶段的样本筛选机制。它可以作为数据加载与梯度更新之间的中间层,动态过滤掉高损失样本,从而提升数据利用效率。这种机制在推荐系统中尤为关键——当模型面对大量行为数据时,如何判断哪些样本是“可信的”,直接决定了训练结果的偏向性与稳定性。
相比于传统的数据清洗或标签修复方法,Co-teaching 的优势在于其内嵌性与低成本:无需额外标注、不依赖外部知识库,适合在 GPU 训练环境中以模块化方式集成。它不是一个“理论上的好点子”,而是一个可以在真实数据环境中运行的策略补强机制,尤其适用于标签不可控、数据更新频繁、模型迭代周期短的数字媒体系统。
这类策略的研究意义在于,它推动了训练逻辑从“理想标签假设”向“标签不确定性适应”的转变,也为平台算法团队提供了更具弹性的建模方式。在数据质量无法保证的前提下,如何构建稳定的学习路径,是当前 AI 与媒体系统融合过程中必须面对的核心问题。
在大规模数字媒体处理与分析的生产环境中,监督学习模型往往依赖人工或半自动生成的标签。然而,标签噪声的存在几乎不可避免,来源包括人工标注不一致、启发式规则偏差以及自动化弱监督方法的局限性。这些噪声会导致模型在训练过程中逐渐记忆错误标签,从而显著降低泛化性能,并在实际部署中引发业务风险。
针对标签噪声的鲁棒性研究已成为机器学习的重要方向。本文旨在通过可控的对称标签噪声注入实验,系统比较两种训练策略在不同噪声水平下的表现:
- 标准交叉熵基线方法(Empirical Risk Minimization, ERM)
- Co-teaching 方法(基于小损失原则的双网络互选策略)
2. 相关工作
2.1 标签噪声类型
标签噪声可分为对称噪声(随机将标签翻转为其他类别)与非对称噪声(标签更可能被翻转为相似类别)。在媒体数据处理中,噪声来源包括:
- 人工标注差异
- 自动化标签生成错误
- 数据采集与传输过程中的元数据丢失或错误
2.2 鲁棒训练方法
- 经验风险最小化(ERM):直接最小化训练集上的平均损失,易在高噪声下过拟合错误标签。
- Co-teaching:由两网络同时训练,每轮互相选择对方的小损失样本进行更新,从而减少错误标签的影响。
3 方法
3.1 基线方法
使用单个 ResNet-18 网络,损失函数为交叉熵,无额外噪声处理机制。
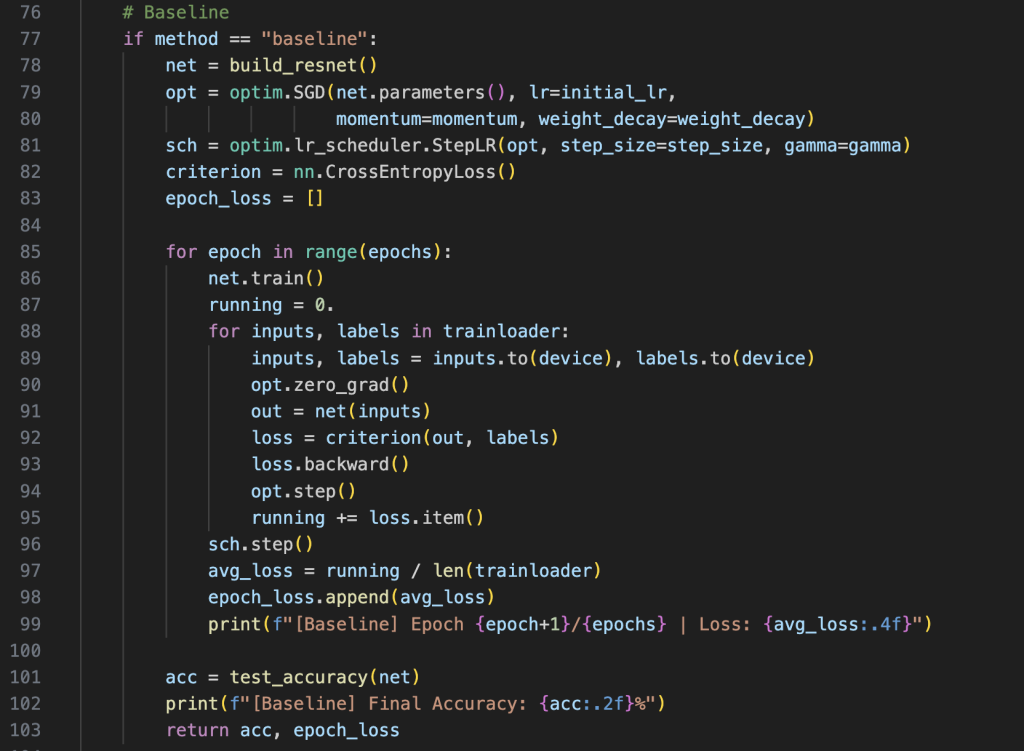
3.2 Co-teaching 方法
使用两个结构相同的 ResNet-18 网络,每轮训练中:
- 各自计算当前批次样本的损失
- 按损失从小到大排序
- 按记忆率(remember rate)选取前若干比例的样本
- 将选出的样本交给另一网络进行更新
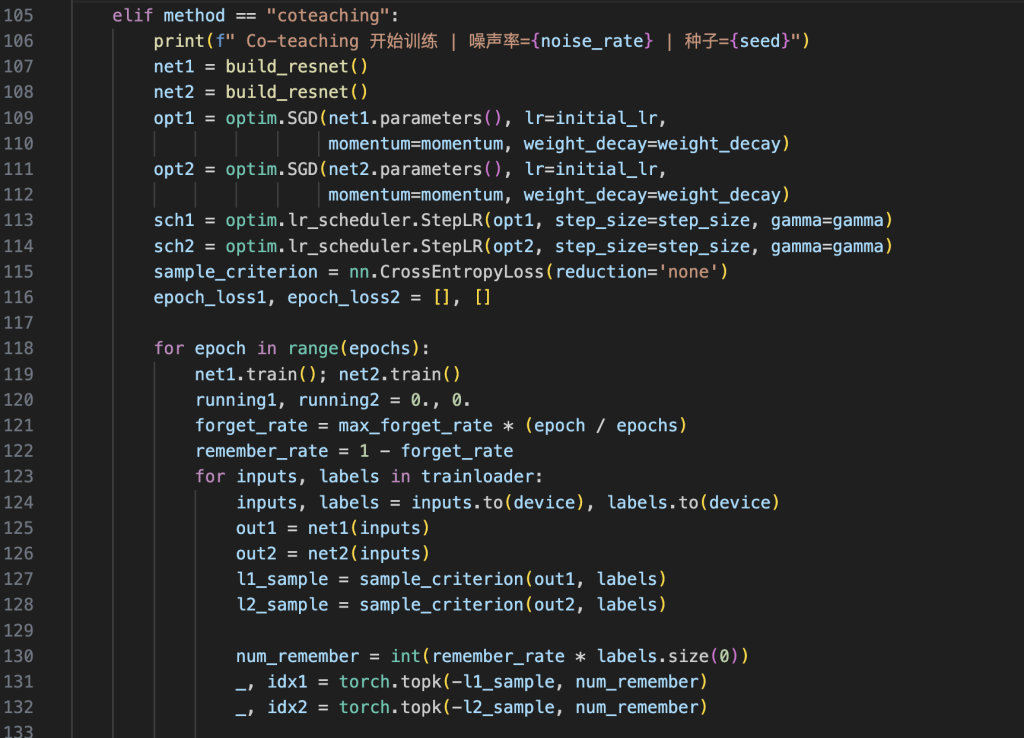
记忆率随训练轮数递减,以逐步过滤掉更多可能的噪声样本。
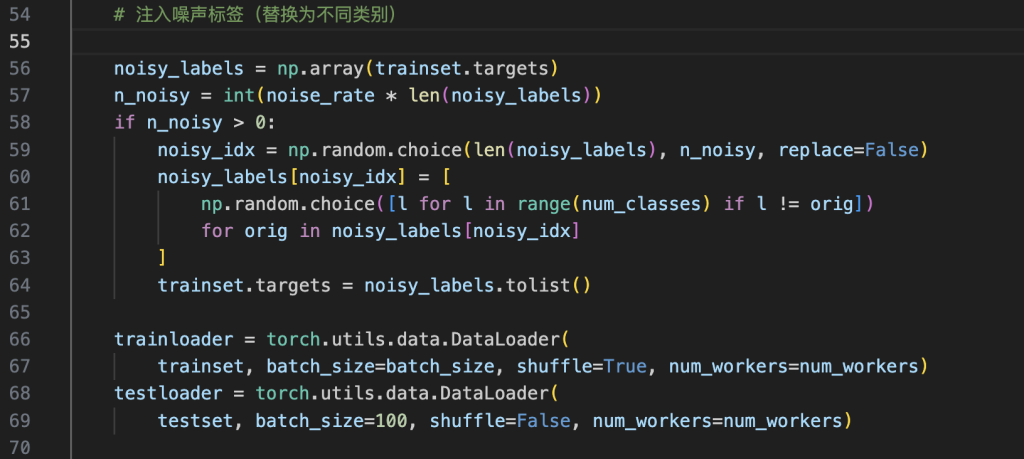
3.3 噪声注入
在训练集上按设定噪声率随机翻转标签,翻转目标类别均匀采样,测试集保持干净。
4 实验设置
- 数据集:CIFAR-10
- 预处理:标准归一化、随机裁剪、水平翻转
- 噪声率:0.00–0.70,步长 0.05
- 随机种子:多种子运行,记录均值与标准差
- 模型结构:ResNet-18
- 优化器:SGD(学习率 0.1,动量 0.9,权重衰减 5e-4)
- 学习率调度:StepLR(每 20 轮衰减 0.1)
- 训练轮数:50
- 批量大小:128
- 评估指标:测试集准确率、每轮损失曲线、结果 CSV 记录
5 实验结果
5.1 准确率趋势
- 随噪声率增加,两种方法准确率均单调下降
- 在低噪声(≤0.20)下,基线方法与 Co-teaching 表现接近,甚至略优
- 在中噪声(0.25–0.50)下,Co-teaching 明显优于基线
- 在高噪声(≥0.55)下,Co-teaching 仍有优势,但在极高噪声(0.70)时偶有基线反超
5.2 稳定性分析
- 随噪声率升高,随机种子间的性能方差显著增大
- Co-teaching 在中高噪声下的方差略低于基线,但在极高噪声下差异缩小
6 讨论与业务启示
6.1 不同噪声环境下的策略建议
- 低噪声:优先使用基线方法,简单高效
- 中噪声:推荐 Co-teaching,能有效抑制错误标签的影响
- 高噪声:结合 Co-teaching 与数据清洗、半监督学习等方法
6.2 部署建议
- 必须进行多随机种子验证,避免偶然性结果
- 在极高噪声下,应监控 Co-teaching 的样本利用率,必要时调整记忆率策略
- 对业务关键任务,可采用多模型集成以降低方差
7 局限性与未来工作
- 数据集仅限 CIFAR-10,需在业务相关数据上验证
- 噪声类型仅为对称噪声,未来应考虑非对称与实例依赖噪声
- 方法仅比较基线与 Co-teaching,后续可扩展至更多鲁棒训练方法
- 评估指标可增加模型校准度、精确率/召回率等业务相关指标
8 结论
本文在可控的对称标签噪声环境下,系统比较了 Co-teaching 与基线方法的鲁棒性表现。结果表明,方法选择应根据噪声水平而定:低噪声下基线足够,中高噪声下 Co-teaching 更优,极高噪声下需结合数据与模型策略共同优化。该研究为实际业务场景中的模型选择与部署提供了可复现、可量化的参考框架。